本文是对于模糊测试方面的小总结,计划三篇;第一篇概述;第二篇afl;第三篇Winafl。非大部头书,只提取关键信息。
本篇为第一篇:概述。
总览
Part 1
- 漏洞 、 模糊测试过程 、 crash分类 、 根本原因分析(RCA)
Part 2
- 使用 AFL 在 linux 上进行模糊测试
Part 3
- 使用 WinAFL 在Windows上进行模糊测试
Part 1 总览
- 漏洞
- 不同类型的漏洞
- 整数溢出
- 栈/堆溢出
- 越界读写 (OOB)
- 释放后使用/双重释放(UAF/DF)
- 人工识别C程序中的漏洞
- 不同类型的漏洞
- 什么是模糊测试?
- 模糊测试的需求
- 模糊测试的种类
- Fuzz一个程序的具体过程
- Crash分析
- Crash追踪
- 根本原因分析(RCA)
- 向供应商/漏洞赏金报告问题
漏洞
软件里的漏洞
- 例如:如果将长度大于1000字节数据的URL get请求发送到Web服务器,服务器可能会崩溃
可用于执行各种恶意的活动
远程执行代码——有人可以远程的执行恶意代码,危害性十足
拒绝服务–可能会使软件或整个系统崩溃
特权升级–从本地帐户到管理员帐户
以上三种都可转换为可利用的Exploits
在恶意网络攻击中使用它们会造成何种危害?
- 导致系统受损,勒索软件,特洛伊木马,僵尸网络,比特币矿工,数据盗窃等
- 行业影响–数据盗窃,生产力损失
常见漏洞类型
- 整数溢出/下溢,栈/堆溢出,超出范围的读/写,释放后使用,双重释放可以转换为漏洞利用
不同类型的漏洞
先说溢出,是指计算机进行运算产生的结果若超出机器所能表示的范围。
溢出有上溢出和下溢出之分,对整型数来说,从正方向超过了数的表示范围,称为上溢出(overflow),从负方向超过了数的表示范围,称为下溢出(underflow)。
就像往水桶里装水,水满则溢,变量也是这样,如果要存储的值超过了变量所能提供的位数,就会出现溢出。
整数溢出(上溢)
它是什么?
- 整数 这一数据类型中的弱点,即它们存储数据的方式。
- 例子:
- unsigned int j
- int i
- int整数的大小为 4 字节,一个字节 8 bit
- MAX 值 : 11111111111111111111111111111111
- 2^32
- Signed vs unsigned?
- MSB(most significant bit 最高有效位)是适用于有符号(signed)整数的
- 1 = 00000000000000000000000000000001
- -1 = 10000000000000000000000000000001
- 有符号整数最大值为 int = **0x7**FFFFFFF
- 无符号整数最大值为 int = **0xF**FFFFFFF
- 在这种情况下会发生什么?
- int i
- unsigned int j
- j = 0xFFFFFFFF + 1
- 结果将变为0,进位1位将被截断
- i= 0x7FFFFFFFF + 1
- 结果将变为-0x80000000(负数)

整数溢出,由于进位会被截断,因此数量非常少;在该案例中直接变成0.
- 我们来举一个真实Apple漏洞例子:
- https://mailman.videolan.org/pipermail/vlc/2008-March/015488.html

在1961行MP4_GET4BYTES函数读取.mov file的长度,苹果的quicktime会将这个值存储在i_len变量里面随后分配一块内存。
问题出在1965行之中,如果我们“精巧”地构造mov文件使其i_len恰好为0xFFFFFFFF,则malloc(i_len+1)就会恰好整数溢出为0,变成分配0空间。它不会报错,但是不会分配所需的内存。配合1966行不断地循环赋值,这些都会存储在缓冲区之中,可能导致代码执行。
整数溢出(下溢)
它是什么?
- int 的大小 = 4 bytes
- Signed vs unsigned?
- signed int 范围 = -0x80000000 to 0x7FFFFFFF
- unsigned int 范围 = 0 to 0xFFFFFFFF
在这种情况下会发生什么?
- int i;
- i = -0x80000000 –1 = 0x7FFFFFFF
- i = 尽可能高的正数

整数下溢后,数量变为非常大,由负数(-)变为正数(+)

栈/堆溢出
栈溢出
- 本地变量存储在栈中
- 栈是有限尺寸
- 溢出局部变量,可损坏堆栈上的其他数据。
- 例子:

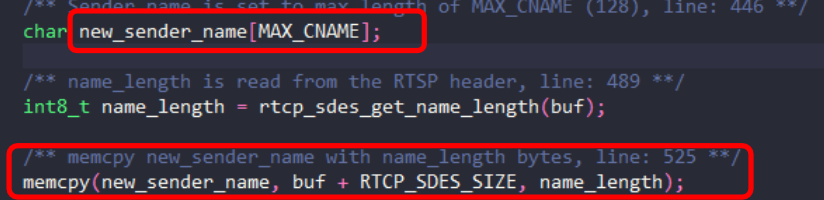
堆溢出
- 动态内存分配
- 从堆中分配
- 堆中的溢出会损坏堆中的其他数据
- 例子:

越界读写
栈越界读写
- 超出堆栈内存允许限度的内存访问或编写操作
- 可能导致地址的违法访问
- 例子:
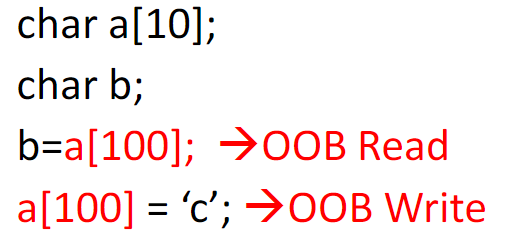
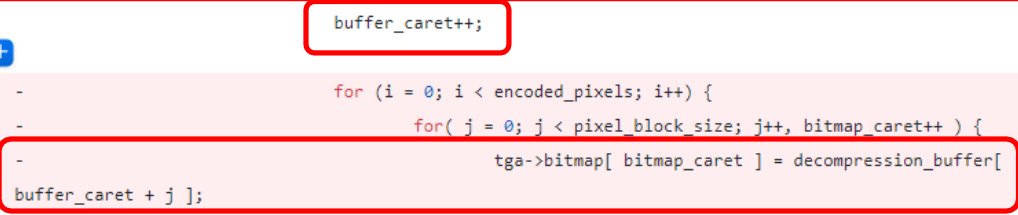
堆越界读写
- 超出堆内存允许限度的内存访问或书写操作
- 可能导致地址的违法访问
- 例子:

UAF 与 Double free 漏洞
Use After Free
- 释放后使用内存
- 可能导致程序崩溃或意外行为
- 例子:


Double Free
- 多次(两次?)释放分配的内存
- 可能导致程序崩溃
- 例子:
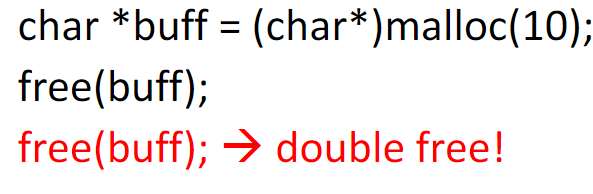
尝试一下:自己动手识别漏洞

追踪BUG 与 模糊测试
追踪BUG
- 手动代码审核
- 需要大量的时间,非常缓慢
- 无法覆盖所有代码路径
- 代码基数大,单人无法充分进行审核
- 不是很有成效
- 重要的BUG可能会被粗心错过
- 无法涵盖所有场景
- 自动化
- 自动错误查找,非常快
- 可以覆盖大多数代码路径
- 无需担心代码的大小
- 可以由个人完成
- 可以自动进一步归类统计有关崩溃、问题,并通知相关人员
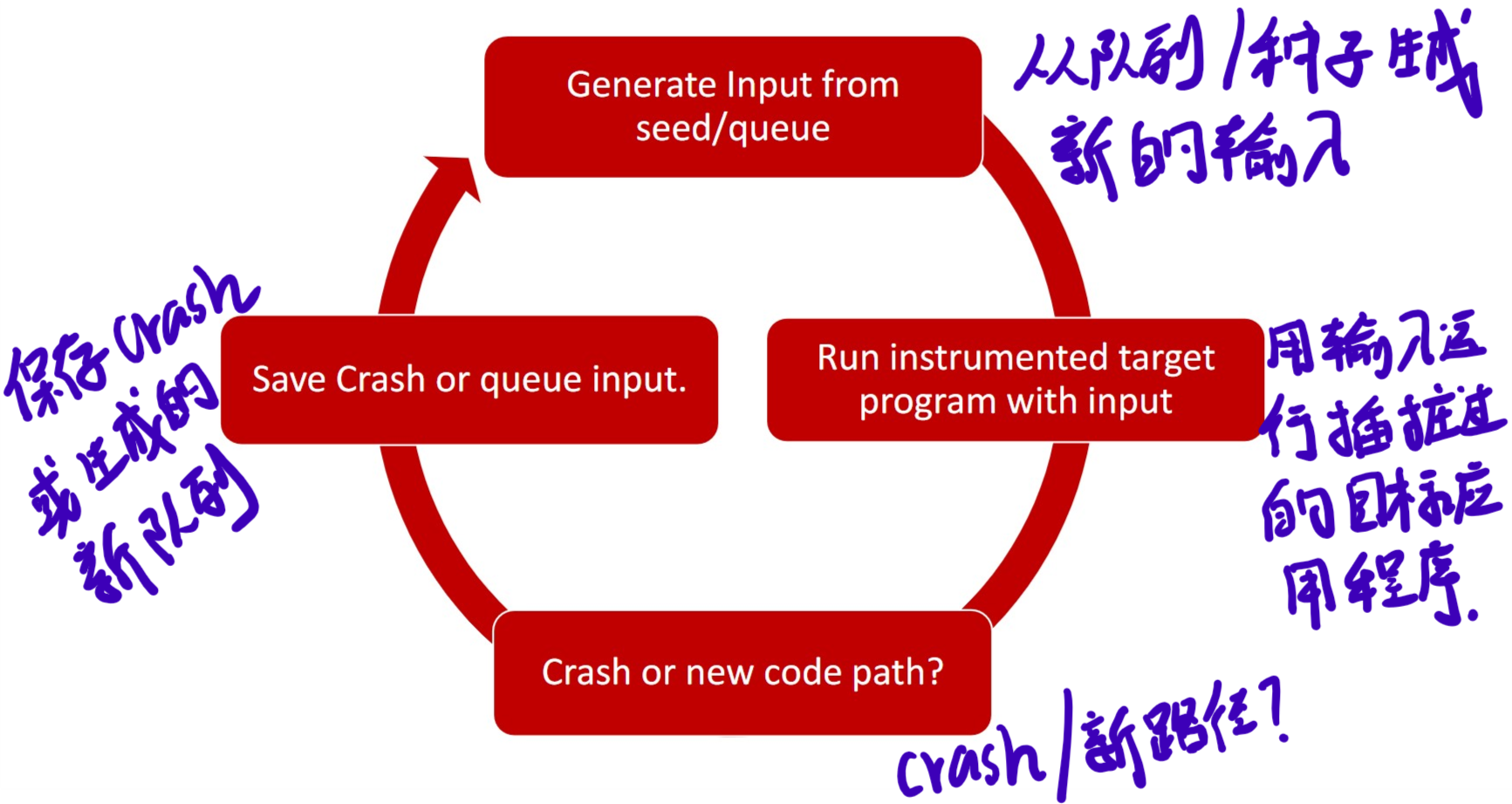
什么是模糊测试
程序中的自动错误查找过程
- 向程序馈送输入
- 实时监控程序的崩溃(crashes)状态
- 保存崩溃测试案例
- 不断生成新的测试案例
- 转到步骤1
模糊测试Fuzzer的分类
愚蠢的Fuzzer
- 完全随机的输入
- 无需了解文件格式/网络协议
- 可能需要很多时间(取决于你的运气)
- 例子:radmasa
改良后的Fuzzer
- 根据预先定义的结构创建输入
- 需要了解文件格式
- 需要了解网络协议
- 例子:peach,sulley
覆盖引导的Fuzzer
- 使用界面监控程序流
- 无需了解文件格式
- 变异文件并检查新代码路径覆盖/崩溃
- 发现新代码路径——>添加到队列
- 崩溃——>保存输入
- 例子:AFL, WinAFL, HonggFuzz, libfuzzer
覆盖率与插桩
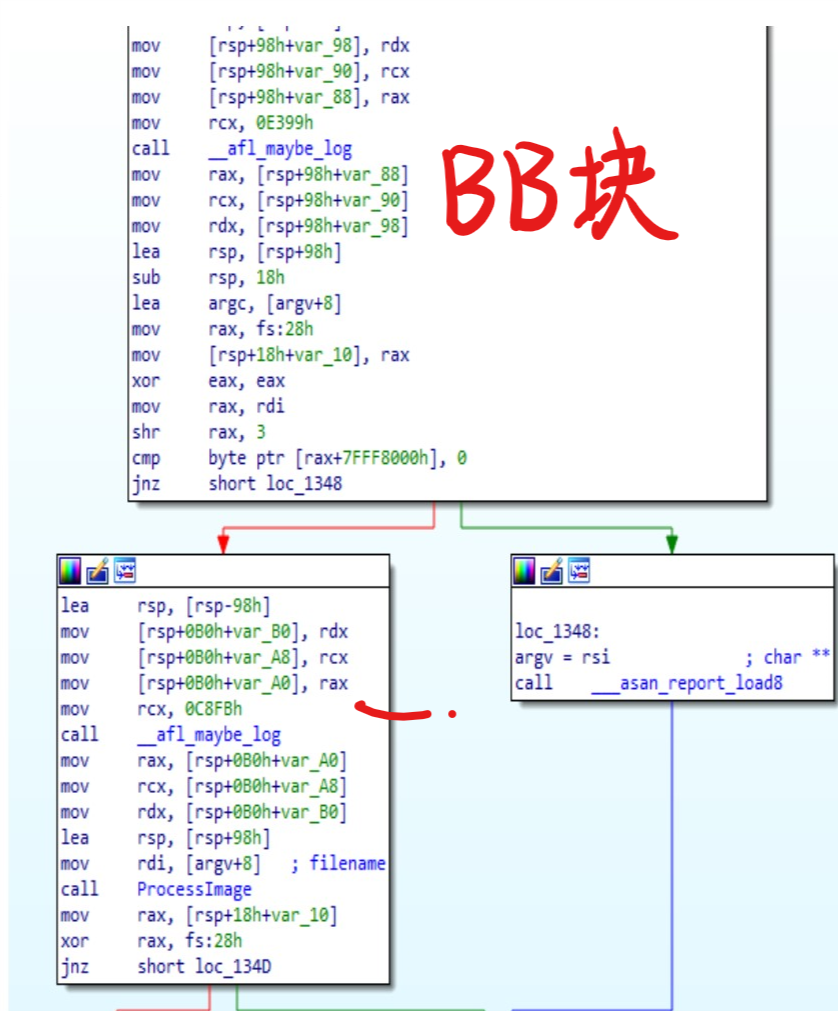
基本块和覆盖率计算
Basic block
- 没有分支的连续代码行
- 入口点–控制进入此基本块
- 退出点-控制转到另一个基本块
Code Coverage

插桩
如何跟踪运行中的程序执行过程?
- 基本方法-添加打印定义的代码和解试
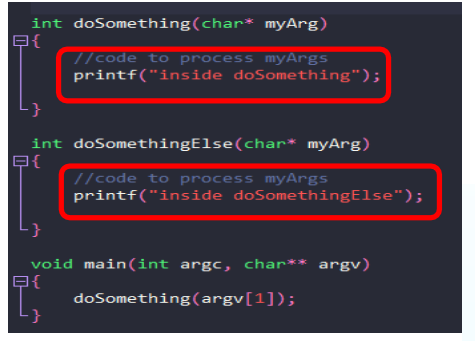
- 无法提供太多数据
- 需要人工的工作
如果源代码可用
- 在编译时插桩
- 在编译过程中加入插桩代码
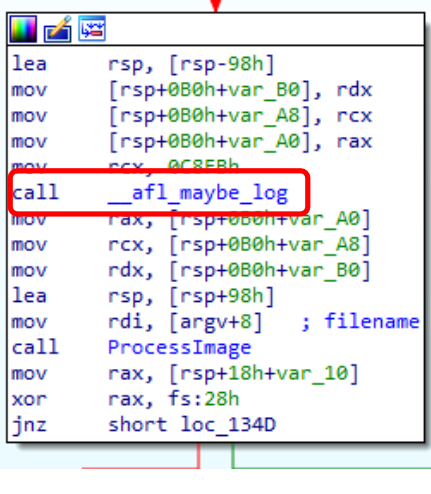
- 可以自动化执行,如实时的覆盖测量,避免人工耗费精力
如果源代码不可用
- 在运行时插桩
- 在运行时添加插桩代码
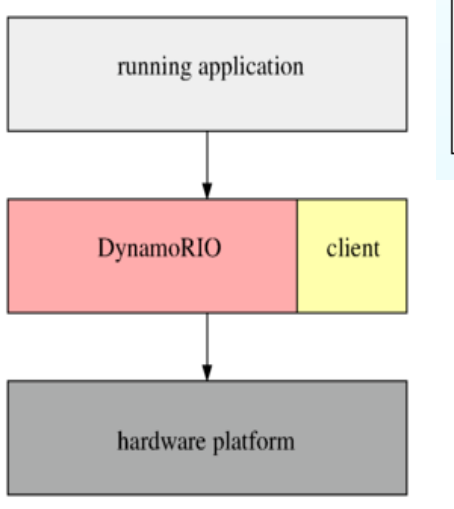
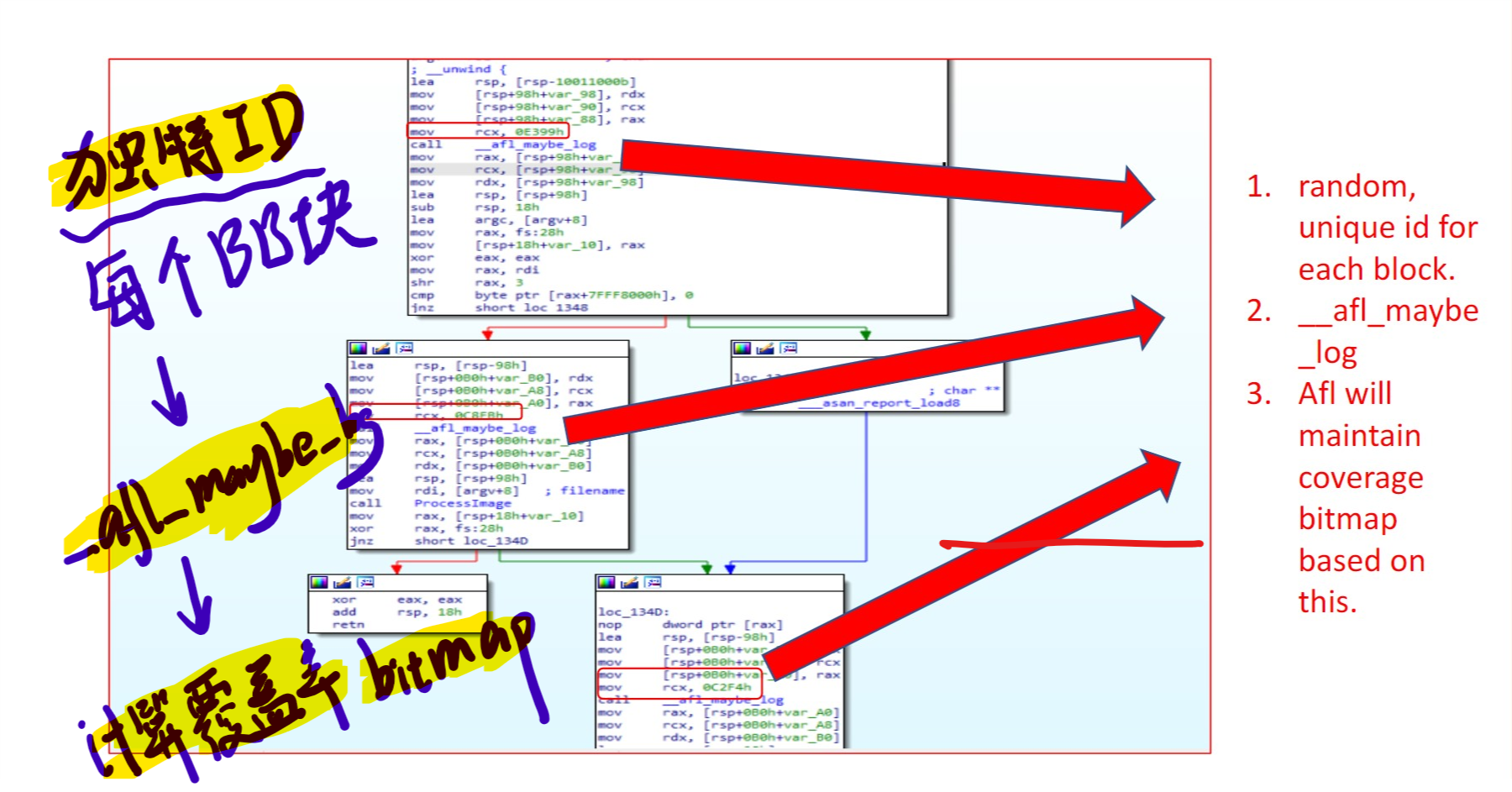
以AFL为例的插桩详细
Fuzz过程
覆盖率引导的模糊测试过程
语料库收集
- 一个好的文件语料库将有助于在短时间内发现路径
- 对于目标软件或lib库,如果附带测试样例文件,可以收集使用
- 使用可用的样例文件
- 搜索 github
- 搜索 Google
语料库精简
- 有一个特别大的语料库是好事还是坏事?
- 什么样的文件尺寸算是特别大?
- 位翻转操作(Bitflip/byteflip)将需要大量时间
- 10MB = 10485760 Bytes
- 如果许多文件触发相同的代码路径怎么办?
- 模糊测试将花费不必要的周期时间来运行它们
- 什么样的文件尺寸算是特别大?
- 需要最小化输入语料库
- 筛选出不会导致新路径的文件,删掉他们
- 筛选出大的文件,删掉他们
- 怎么做?
- afl-cmin–iinput –o mininput–./program @@
Crashes——>探寻根因——>确认漏洞
根因分析(Root cause analysis RCA)
- 我们发现了一个崩溃——现在要干什么?
- 文件中的哪个字段函数部分?
- 该字段函数的价值?
- 程序中的哪个条件触发的?
1——2个Crash
- 人工分析
成百上千的Crashes?
如何分析分类它们?
- Crashwalk, atriage, afl-collect,BUGid…
向供应商/或Bug 赏金机构报告
- 首先向供应商报告
- 大部分供应商有一个类似于 security@vendor.com的安全邮箱
- 不要公开披露自己的发现
- 你可能会因为crash而得到奖励,或者CVE编号